 |
|
|||||
 |
(1)オープンデータ(LOD)の利用の問題点
数年前から地方公共団体では、積極的にインターネットのWEB上にオープンデータ(LOD:Linked Open Data)を公開するようになってきました。
データの種類は、決算情報、自治体人口・世帯情報、施設情報、各種統計情報等いろいろなデータがあるのですが、データの公開方法、分類方法は各機関で独自に行っているので、複数の組織に共通のあるデータを比較検討したい場合等は、全て自分でサイトを探してデータをダウンロードする必要があり、あまり使い勝手がよくありませんでした。
(2)LinkData.org について
例えば、日本の各自治体の人口統計情報を素早く入手したい場合、今までは検索サイトでキーワードを'人口統計'と入力して、検索結果をひとつひとつチェックしたり、各自治体のオープンデータサイトをWEBで開き、人口統計資料のリンクを探したりしてデータを収集していました。
こんな時、'LinkData.org'というサイトを見つけ、非常に助かっております。

Link Data.org HP(Link Data.orgより)
〜Link Data.orの簡単な使用法〜
(1).LinkData.org のトップページを開く
(2).[リソースを検索]のキーワード入力欄に'人口統計'と入力し、[Search]ボタンをクリック
(3).検索結果として、該当箇所がマーカー表示されたマップとその下に該当リンク一覧が表示されます。
該当箇所がマーカー表示されたマップ(Link Data.orgより)

該当リンク一覧(Link Data.orgより)
(4).マーカーのリンク、またはリンク一覧のリンクをクリックすると、データ情報が表示され、すぐにダウンロードすることができます。
驚いたことにEXCEL等のテーブルデータはダウンロードせずにWEB上で[テーブルデータの内容]をクリックすればすぐに見ることができます。
また、CSV形式にテキスト変換されたデータやRDF形式のデータもダウンロードすることができます。
データ情報の表示(Link Data.orgより)
(3)テーブルデータ以外のオープンデータの取り扱いについて
LinkData.orgは、テーブルデータに特化して非常に協力な検索機能を提供しています。
地方公共団体のオープンデータサイトではそのほとんどがテーブル形式(EXCEL,CSV等)で提供されていますから、オープンデータサイトにあるデータに限ればLinkData.orgを活用すれば大体のデータは取得可能になります。
しかし、オープンデータは必ずしもテーブルデータだけとは限りません。
身近な例では入札の公告情報や入札結果情報等、それに付随する特記仕様書等、自治体の条例等の記録文書など中身を見てみないと解らない文書データも数多くあります。そのような文書データを検索、解析する為には一旦文書を保存し、その文書から文字をテキスト抽出し、そのテキストをデータベースに登録し、それを全文検索処理できる機能が必要となってきます。
(4)全文検索システムについて
ダウンロードしたオープンデータを全文検索するには、まずそのデータからテキストデータを抽出し、抽出したテキストをデータベースに登録し、全文検索用のインデックスを作成する必要があります。
以下に、その為のツール、システムについて紹介します。
(5)無償で使えるテキスト抽出ツールについて
(1).xdoc2txt
日本で開発された、非常にすぐれた汎用のテキスト抽出ソフトです。
残念ながらWindows版しかありませんが、ほとんどのドキュメント形式に対応しています。
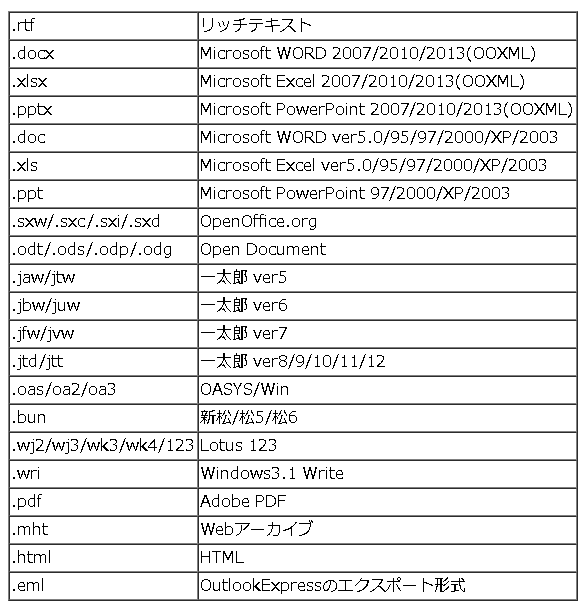
xdoc2txtが対応しているドキュメント形式(xdoc2txt公式HPより)
(2).pdftotxt
xpdfというPDF用ユーティリティーに含まれるテキスト抽出プログラムです。
ライセンスはGPL(フリー)で、日本語対応には日本語パッケージを付け加える必要があります。
Windows,linux,Mac版があります。
PDFからの抽出のみ対応します。
(6)全文検索システム用データベース
通常のデータベースのシステムで、あるテーブルのテキスト項目の部分一致検索を行う際、一般的には LIKE '%キーワード%'を使用しますがこの方法では全文検索用インデックスが無い為、検索が非常に遅くなってしまいます。
これゆえ高速な全文検索可能なデーターベースシステムでは全文検索インデックス機能が付加されています。
この機能を付加した場合と通常の場合を比較すると、検索スピードが2桁〜3桁ほど違ってきますので、全文検索を自分のデータベースでやりたければ全文検索インデックス機能は必須となります。
全文検索対応のデータベースエンジンは商用ではもちろんありますが、かなり高額です。
数年前までは個人や一般の企業で自力で全文検索システムを構築することはかなり難しかったのですが、2〜3年前から比較的容易に構築することが可能になってきました。
それは以下にあげるようなオープンソースの全文検索インデックスシステムが登場してきたことが要因となっております。
(1).Groonga
GroongaはC言語で書かれた国産の高速な全文検索エンジンで、C言語から呼び出すことが可能な全文検索ライブラリとしての機能を有し、単体でも全文検索サーバとしての機能を有します。
オープンソースのデータベースシステムであるPostgresqlやMySQL用にも、それぞれPgroonga,Mroongaというインターフェースが提供され、容易に使用することが可能です。
特徴はデータ件数が増えても検索スピードがあまり低下しない点と、インデックス作成スピードが高速であるという点です。欠点はインデックスサイズが非常に大きくなるという点です。
(2).pg_bigm
2013年にNTT DATAの澤田雅彦氏がPostgreSQL用に開発した全文検索用ライブラリです。
この機能を通常のPostgreSQLデータベースに付加する場合は、ソースコンパイルの知識が必要となります。
現状ではLinuxシステムのみで動作します。
特徴はデータ件数が増えても検索スピードがあまり低下しない点と、インデックスサイズが小さいという点です。
欠点はインデックス作成に時間がかかるという点です。
(7)まとめ
オープンデータの利用推進が叫ばれて既に10年近くになります。
オープンデータの公開は各組織で相当進んでいますが、利用方法についてはまだまだと言えます。
みなさんも上記サイトやツール等を利用してオープンデータを現在の業務等に活用してみてはいかがでしょうか。